아래의 내용은 David Silver교수님의 강의 자료를 통해 정리했으며
팡요랩 강화 학습 강의를 기반으로 내용을 정리했다.
https://www.youtube.com/watch?v=NMesGSXr8H4&ab_channel=%ED%8C%A1%EC%9A%94%EB%9E%A9Pang-YoLab
현재 meta learning에서 MAML에 대해 공부하고 있는데 MAML + RL에 대한 내용이 있어서 이왕 하는 김에 RL 공부를 간단하게 해보고자 한다.
1강은 강화학습이 뭔지? 강화학습에서 사용되는 용어, 개념에 대한 내용이 주를 이루고있다. 핵심이 되는 내용만 간단하게 정리할 예정으로.. 시작해 보자!
강화학습이란?
시행착오를 통해 학습하며 에이전트(학습하는 주체?)가 실수, 보상을 통해 학습을 하여 목표를 찾아가는 알고리즘이다. 기존에 Supervised Learning에서는 데이터, 라벨이 주어져서 모델이 데이터에 맞는 라벨들을 잘 맞추게 학습해 간다면, 강화학습은 보상(Rewards)을 최대화하는 방향으로 모델(강화학습에서는 에이전트)이 학습하는 것을 의미한다. 그럼 강화학습에서 사용되는 주 용어들의 개념에 대해 살펴보자.
Rewards
Reward는 번역하면 보상이라는 의미이다. 에이전트가 어떤 행동을 했을 때, 올바른 정답값(예를 들어 미로에서는 탈출 지점)에 도달했으면 잘했으니 Reward를 주는 것이다. 강화학습에서 목표는 이 축적된 Reward를 maximization 하는 에이전트를 만드는 것이다. 지도학습에서는 Loss를 minimization 하는 모델을 만들었는데 반대이다. Reward는 수식으로 \(t\)에서의 보상으로 \(R_{t}\)로 표기한다.
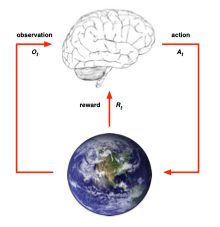
Agent and Environment
뇌는 Agent이고 지구는 Environment인데 Agent는 학습을 하는 주체라 생각했고 Environment는 Agent에게 전달되는 정보의 모든 것이라고 생각한다. 그림을 따라고 보면 먼저 Agent는 action \(A_{t}\)을 Envirionment에 전달하고, Environment는 받은 action을 토대로 observation \(O_{t}\)와 Reward \(R_{t}\)를 다시 Agent에게 전달한다.
예를 들어 어떤 사람이 미로를 빠져나간다고 하면 그 사람이 agent가 될 것이고 이 사람이 오른쪽으로 가면 오른쪽으로 이동함에 따라 주변 지형이 바뀔 것(Observation)이고 해당 위치가 탈출로 인지(Reward)에 대한 정보를 주는 것이 Environment라고 생각한다.
History and State
History
History는 이전의 observations, actions, rewards에 대한 sequence로 아래와 같이 정의한다. 즉, 이전 기록들(정보)을 가지고 있음.
$$ H_{t} = O_{1}, R_{1}, A_{1} .... A_{t-1}, O_{t}, R_{t}\ $$
State
State는 다음에 어떤 행동을 취할지 결정할 때 필요한 정보들을 의미한다. 과거 history 정보를 통해 state를 만들기 때문에
$$ S_{t} = f(H_{t})\ $$
history에 대한 어떤 함수라고 할 수 있다.
Markov State
만약 아래의 수식을 만족하면 "state \(S_{t}\)는 Markov 하다"라고 표현한다.
$$ P [S_{t+1} | S_{t}]= P[S_{t+1} | S_{1},... S_{t}]\ $$
수식을 살펴보면 \(S_{1}...S{t}\)까지의 정보들로 \(S_{t+1}\)가 발생할 확률은 \(S_{t}\)인 현재상태의 조건에서 발생할 확률과 같다는 의미이다. 즉, 미래의 상태를 결정하는 데 있어서 현재 state만을 필요로 한다는 의미인데 이는 현재 state에는 과거의 state에 대한 정보들이 어느 정도 포함되어 있느니 그런 것 아닐까 싶다. 자료에서는 미래의 state는 과거의 state에 independent 하다고 말한다.
Agent의 구성요소
Agent는 Policy, Value function, Model 3개로 구성되어 있다. Policy먼저 알아보자.
Policy
Policy는 agent의 행동을 의미한다. Policy는 \(\pi(s)\)의 형태로 표기하며 어떤 state에서 어떤 행동(action)에 대한 의미이다.
대부분 \(\pi(a|s) = P[A_{t}=a | S_{t}=s]\)와 같이 현재 state s일 때 action a를 할 확률로 표현한다.
Value Function
Value Function은 미래의 Reward의 예측치를 의미한다. 현재 state의 좋고/나쁨을 평가하는 값이기도 하다.
$$ v_{\pi}(s) = \mathbb{E}_{\pi}[R_{t+1} + \gamma R_{t+2}... + .... | S_{t}=s] \ $$
수식을 풀어서 이야기해보면 state S 상태에서 \(\pi\)라는 Policy를 따를 때, 미래에 얻을 수 있는 총 Reward의 기댓값을 의미한다. 여기서 \(\gamma\)는 discount factor로써 0~1 사이의 값을 가지며 미래에서의 Reward와 현재의 Reward의 가치는 다르기 때문에 이를 판단해 주기 위한 값이라고 생각하면 된다.
Model
Model은 다음 environment가 어떻게 될지 예측하는 것을 의미한다.